12.11 Remarks and exercises
12.11.1 Operator decompositions
Analogously to how we can factor polynomials into linear parts, or factor numbers into prime divisors, we can “factor” matrices into smaller components. Doing so often helps us to better understand the geometry of the situation: we might be able to understand the transformation described by a single matrix as “some reflection, followed by some rotation, followed by some scaling”. For us, one specific use of such a “factorisation” (known formally as an operator decomposition) is in better understanding various operator norms, as we explain in Exercise 12.11.2.
Here are three operator decompositions that are particularly useful in quantum information theory. The second is for arbitrary operators between Hilbert spaces, the first and third are for normal endomorphisms (i.e. normal operators from one Hilbert space to itself).
- Spectral decomposition.
Recall Section 4.5: the spectral theorem tells us that every normal operator
A\in\mathcal{B}(\mathcal{H}) can be expressed as a linear combination of projections onto pairwise orthogonal subspaces. We write the spectral decomposition ofA asA = \sum_k \lambda_k |v_k\rangle\langle v_k| where\lambda_k are the eigenvalues ofA , with corresponding eigenvectors|v_k\rangle , which form an orthonormal basis in\mathcal{H} .
In matrix notation, we can write this as
- Singular value decomposition (SVD).
We have already mentioned the SVD in Exercise 5.14.13 when discussing the Schmidt decomposition, but we recall the details here.
Consider any (non-zero) operator
A\in\mathcal{B}(\mathcal{H},\mathcal{H}') . From this, we can construct two positive semi-definite operators:A^\dagger A\in\mathcal{B}(\mathcal{H}) andAA^\dagger\in\mathcal{B}(\mathcal{H}') . These are both normal, and so we can apply the spectral decomposition to both. In particular, if we denote the eigenvalues ofA^\dagger A by\lambda_k , and the corresponding eigenvectors by|v_k\rangle , then we see that the vectors|u_k\rangle \coloneqq \frac{1}{\sqrt{\lambda_k}}A|v_k\rangle form an orthonormal system in\mathcal{H}' (and are, in fact, eigenvectors ofAA^\dagger ), since\begin{aligned} \langle u_i|u_j\rangle &= \frac{1}{\sqrt{\lambda_i}\sqrt{\lambda_j}} \langle v_i|A^\dagger A|v_j\rangle \\&= \frac{\lambda_j}{\sqrt{\lambda_i}\sqrt{\lambda_j}} \langle v_i|v_j\rangle \\&= \delta_{ij}. \end{aligned} We define the singular valuess_k ofA to be the square roots of the eigenvalues ofA^\dagger A , i.e.s_k^2=\lambda_k . These singular values satisfyA|v_k\rangle=s_k|u_k\rangle by construction, and so we can writeA = \sum_k s_k|u_k\rangle\langle v_k| which we call the singular value decomposition (or SVD). This decomposition holds for arbitrary (non-zero) operators as opposed to just normal ones, and also for operators between two different Hilbert spaces as opposed to just endomorphisms. In words, this decomposition says that, givenA , we can find orthonormal bases of\mathcal{H} and\mathcal{H}' such thatA maps thek -th basis vector of\mathcal{H} to a non-negative multiple of thek -th basis vector of\mathcal{H}' (and sends any left over basis vectors to0 , if\dim\mathcal{H}>\dim\mathcal{H}' ).
In matrix notation, we can write this as
Geometrically, we are decomposing any linear transformation into a composition of a rotation or reflection
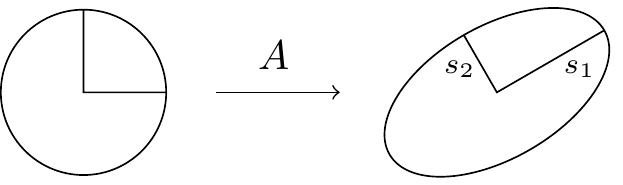
- Polar decomposition.
Let
A\in\mathcal{B}(\mathcal{H}) be a normal arbitrary operator. Since it is an endomorphism, it is represented by a square matrix. Forgetting thatA is normal for a moment, we know that its SVD takes the form\begin{aligned} A &= U\sqrt{A^\dagger A} \\&= \sqrt{AA^\dagger}U \end{aligned} where the unitary matrixU connects the two eigenbases:U=\sum_k|u_k\rangle\langle v_k| . We shall return to this unitaryU shortly.
Since
If we decompose the eigenvalues of
12.11.2 More operator norms
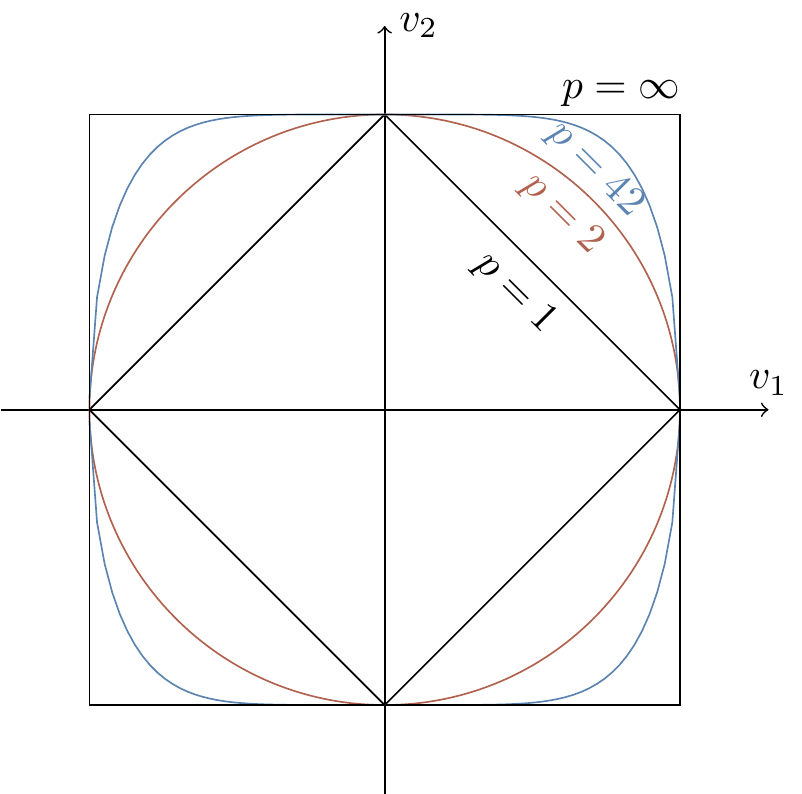
We have already seen, all the way back in Section 1.11.2253, how the Euclidean norm (from which we get the Euclidean distance) is the special case
You might recall that we named the Cauchy–Schwartz inequality as arguably the most useful inequality in analysis.
Well it turns out that it is actually the special case
Hölder’s inequality.
Let
We will come back to the relevance of these
Throughout, let
Spectral norm. This one is so frequently used that it is often simply called the operator norm and denoted simply by
\|\cdot\| . It is the maximum length of the vectorA|v\rangle over all possible normalised vectors|v\rangle\in\mathcal{H} , i.e.\|A\| \coloneqq \max_{|v\rangle\in S_{\mathcal{H}}^1}\Big\{ |A|v\rangle| \Big\} (whereS_{\mathcal{H}}^1 is the unit sphere in\mathcal{H} , i.e. the set of vectors of norm1 ). From this definition, one can actually show that the norm is given by the largest singular value:\|A\| = \max_k s_k. Trace norm. This is given by the sum of the singular values of
A , i.e.\|A\|_{\operatorname{tr}} \coloneqq \sum_k s_k but note that we can rewrite this using the polar decomposition (from Section 12.11.1) as simply\|A\|_{\operatorname{tr}} = \operatorname{tr}|A|. Frobenius norm. We have mentioned a few times how inner products give rise to norms, and you might remember that we introduced an inner product on
\mathcal{B}(\mathcal{H}) a while ago: the Hilbert–Schmidt norm254\begin{aligned} (A|B) &\coloneqq \operatorname{tr}A^\dagger B \\&= \sum_{i,j} A_{ij}^\star B_{ji}. \end{aligned} The Frobenius norm is the norm induced by this inner product, i.e.\begin{aligned} \|A\|_F &\coloneqq \sqrt{(A|A)} \\&= \sqrt{\operatorname{tr}(A^\dagger A)} \\&= \sqrt{\sum_{i,j}|A_{ij}|^2}. \end{aligned}
Let’s study the relation between the operator norm and the trace norm first.
By definition, we see that
We can actually use this inequality to recover either the operator or the trace norm, by maximising: for any fixed
One final special case to point out is what happens if
Now we finally return to the relevance of
12.11.3 Fidelity in a trace norm inequality
There is a useful inequality involving the trace norm:
Let
Writing
One particularly nice application of this inequality arises when we take
12.11.4 Hamming distance
Show that the Hamming distance (defined in Section 12.1) is indeed a metric.
12.11.5 Operator norm
Prove the following properties of the operator norm:
\|A\otimes B\|=\|A\|\|B\| for any operatorsA andB - If
A is normal, then\|A^\dagger\|=\|A\| - If
U is unitary, then\|U\|=1 - If
P\neq0 is an orthogonal projector, then\|P\|=1 .
Using the singular value decomposition256, or otherwise, prove that the operator norm has the following two properties for any operators
- Unitary invariance:
\|UAV\|=\|A\| for any unitariesU andV - Sub-multiplicativity:
\|AB\|\leqslant\|A\|\|B\| .
Recall that we say that
- Prove that, if
V approximatesU with precision\varepsilon , thenV^{-1} approximatesU^{-1} with the same precision\varepsilon .
Using the Cauchy–Schwartz inequality, or otherwise, prove the following, for any vector
|\langle\psi|A^\dagger B|\psi\rangle|\leqslant\|A\|\|B\| .
12.11.6 Tolerance and precision
Suppose we wish to implement a quantum circuit consisting of gates
We want our approximate circuit to be within some tolerance
How small must
12.11.7 Statistical distance and a special event
- Show that, if
p andq are probability distributions on the same sample space\Omega , thend(p,q) = \max_{A\subseteq\Omega}\{|p(A)-q(A)|\}. - By definition, the above maximum is realised for some specific subset
A\subseteq\Omega , i.e. there exists some event (described by the set of outcomesA ) that is optimal in distinguishingp fromq . What is this event?
12.11.8 Joint probability distributions
If we simultaneously sample two random variables from the same probability space, then we obtain a joint distribution:
So let
12.11.9 Distinguishability and the trace distance
Say we have a physical system which is been prepared in one of two states (say,
How does this probability change if the states
\rho_0 and\rho_1 are not equally liked, but instead sent with some predetermined probabilitiesp_0 andp_1 , respectively?Suppose that you are given one randomly selected qubit from a pair in the state
|\psi\rangle = \frac{1}{\sqrt{2}}\left( |0\rangle\otimes\left( \sqrt{\frac23}|0\rangle - \sqrt{\frac13}|1\rangle \right) + |1\rangle\otimes\left( \sqrt{\frac23}|0\rangle + \sqrt{\frac13}|1\rangle \right) \right) from Exercise 8.8.1. What is the maximal probability with which we can determine which qubit (either the first or the second) we were given?
Think how far you’ve come since then!↩︎
Here we drop the factor of
\frac{1}{2} that we sometimes included for simplifying certain calculations.↩︎This is the non-commutative version of the identity
a^2-b^2=(a+b)(a-b) .↩︎Hint: recall that
|p_U-p_V|\leqslant 2\|U-V\| .↩︎Hint:
\begin{aligned}d_{\operatorname{tr}}(p,q)&= 1 - \sum_x \min\{p(x),q(x)\}\\&\leqslant 1 - \sum_x p(x,x)\\&= \Pr(x\neq y).\end{aligned} ↩︎