6.6 Quantum randomness
The experimental violations of the CHSH inequality have shown us that there are situations in which the measurement outcomes are truly unknown the instant before the measurement is made, and so the answer must be “chosen” randomly. We can make use of this randomness in a number of different ways, the most obvious example of which being a random number generator. Indeed, we have already met one suitable implementation:
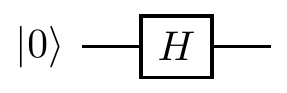
The state before measurement is
This randomness generator works well as long as we know how it’s been built, i.e. that it really is just a Hadamard gate, that the input qubit really has been prepared in the state
A protocol is device independent if its security doesn’t depend on trusting the devices on which it is implemented. In other words, it has no reliance on trusting the third party who supply you with the devices.
We can rule out one thing from the start, namely deterministic behaviour. If we behave deterministically then we have no hope, since the third party can take this into account and potentially find a way to always fool us. But there is another approach that we can try: rather than directly trying to verify the veracity of any given device, we can try to use it to turn a small amount of true randomness into a larger amount. This is the idea of randomness expansion.
Starting from an initial seed of private randomness (completely unknown to any other party), randomness expansion is the process of extending this to a larger amount of randomness that remains completely private.
Let’s consider a different device: one that produces pairs of qubits in singlet states and gives one of its qubits to Alice and one to Bob.
If Alice then measures her qubit in the
Using the idea of randomness expansion, let’s assume that they start with some shared random private seed: some
Why does this help? Well, if somebody has manipulated the device that produces the pairs, then they need to be sure that they haven’t altered the pairs that Alice and Bob are testing on. But they cannot know in advance which pairs that will be, and so they cannot risk manipulating anything.136
In the fraction
Note that we’re pushing the problem somewhere else: how can they come up with this shared private seed in the first place? This is the problem of key distribution, and we’ll return to this again later.↩︎
One can be much more quantitative about this by using Chernoff bounds for a simple strategy of “choose at random which pairs to manipulate”, but a full proof of security is much more involved than we would like to be here.↩︎