14.7 Error-correcting conditions
We can summarise the notion of a stabiliser code that we have defined rather succinctly: everything is determined by picking a stabiliser group, i.e. an abelian subgroup
By setting up some ancilla qubits and constructing appropriate quantum circuits305, we can enact any logical operator in such a way that we also measure an error syndrome, which points at a specific error family. But unlike in our study of the Steane code in Section 14.3, we can no longer simply apply the corresponding operator to fix the error, because the error is a whole coset — it contains many individual Pauli operators.
To fix an example to keep in mind, we return yet again to the three-qubit code.
In Figure 14.8 we draw a diagram grouping together all the elements of
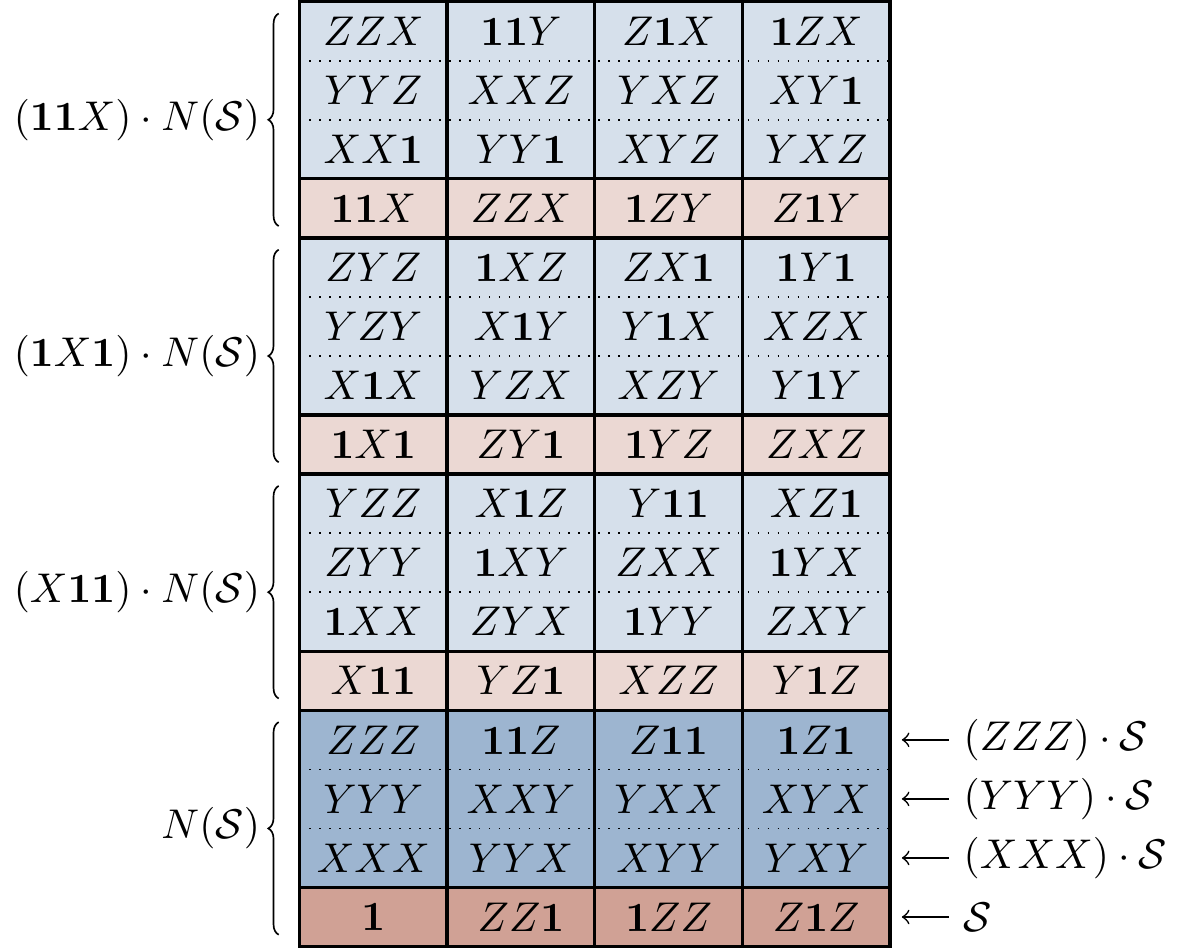
Figure 14.8: The entire group
As we can see by looking at Figure 14.8, if we somehow measure an error syndrome pointing to the error family
In other words, if we assume that only single bit-flip errors can occur, then the stabiliser formalism describes errors in exactly the same way as before, since the error families are in bijection with the physical errors. But here is where the power of the stabiliser formalism can really shine through, since it allows us to understand what type of error scenarios our code can actually deal with in full generality. That is, rather than thinking about a code as something being built to correct for a specific set of errors, the stabiliser formalism lets us say “here is a code”, and then ask “for which sets of errors is this code actually useful?”. The answer to this question lies in understanding how any set of physical errors is distributed across the error families, and we can draw even simpler versions of the diagram in Figure 14.8 to figure this out.
Returning to the scenario where we assume that only single bit-flip errors can occur, we can mark the corresponding physical errors in Figure 14.8 — namely
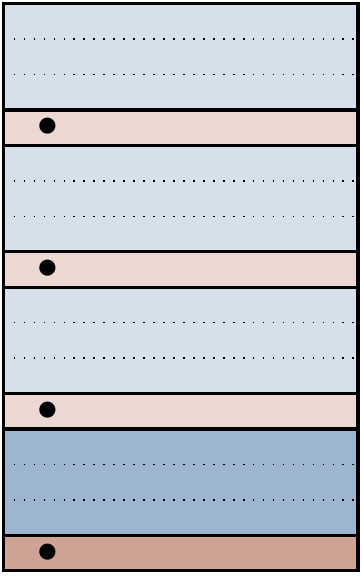
Figure 14.9: All specific
As we said above, if each error family (i.e. coset) contains exactly one physical error (i.e. Pauli operator), then we already know how to apply corrections based on the error-syndrome measurements. In terms of the diagram in Figure 14.9, this rule becomes rather simple: if each error family contains exactly one dot, then we can error correct.
But can we say something more interesting than this? Well, let’s consider what happens if we have a diagram that looks like this:
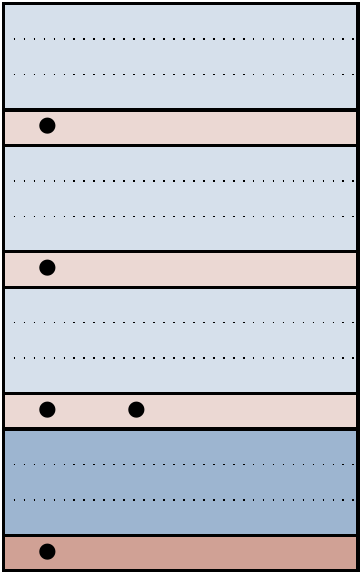
That is, we’re considering a scenario where there are two possible physical errors that can occur for a physical error syndrome.
In the example of the three-qubit code, we’re looking at the scenario where any single bit-flip error can occur, but also the operator
Here’s the fantastic fact: in this case, it doesn’t matter!
Say we pick
To prove this, we just return to the definition of cosets and the properties of the Pauli group.307
If two physical errors
We also get the converse statement from this argument: if any family contains dots in different rows, then we cannot error correct.
This is because we need
So is this the whole story? Almost, but one detail is worth making explicit, concerning maybe the most innocuous looking error of all: the identity error family. Consider a scenario like the following:
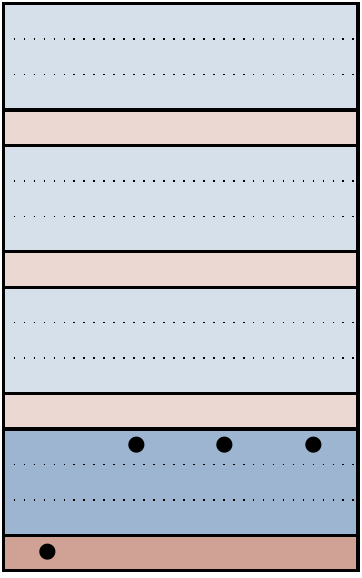
In the case of the three-qubit code, this corresponds to the possible physical errors being single phase-flips
An error-dot diagram describes a perfectly correctable set of errors if and only if the following two rules are satisfied:
- In any given error family, all the dots are in the same row.
- Any dots in the bottom error family are in the bottom row.
(The second rule follows from the first as long as the scenario in question allows the possibility for no errors to occur.)
Of course, we can state these conditions without making reference to the dot-error diagrams, instead using the same mathematical objects that we’ve been using all along. Proving the following version of the statement is the content of Exercise 14.11.12.
Let
Sometimes we might not specify that
You might notice that we’ve been sometimes been saying “perfectly correctable” instead of just “correctable”. This is because there might be scenarios where we are happy with being able to correct errors not perfectly, but instead merely with some high probability.
These dot-error diagrams are also able to describe more probabilistic scenarios. We have been saying “single-qubit errors”, but we could just have well have been saying “lowest-weight errors”, and then the assumption that errors are independent of one another means that higher-weight errors happen with lower probability. But the stabiliser formalism (and thus the error-dot diagrams) don’t care about this “independent errors” assumption! What this means is that we could refine our diagrams: instead of merely drawing dots to denote which errors can occur, we could also label them with specific probabilities. So we could describe a scenario where, for example, one specific high-weight error happens annoyingly often.
One last point that is important for those who care about mathematical correctness concerns our treatment of global phases.309 We do need to care about global phases in order to perform error-syndrome measurements, but once we have the error syndrome we can forget about them. In other words, we need the global phase in order to pick the error family, but not to pick a representative within it.
We will see these circuits soon, starting in Section 14.9.↩︎
Formally, we can think of ignoring phase as looking at the quotient of
\mathcal{P}_3 by the subgroup\langle\pm\mathbf{1},\pm i\rangle , which results in an abelian group.↩︎This is one of those arguments where it’s easy to get lost in the notation. Try picking two physical errors
P_1 andP_2 in the same row somewhere in Figure 14.8 and following through the argument, figuring out whatE ,P ,P'_1 , andP'_2 are as you go.↩︎Just to be clear, if we knew which physical errors took place, then we wouldn’t have to worry about error correction at all, because we’d always know how to perfectly recover the desired state. And remember that we can’t measure to find out which physical error took place, since this would destroy the state that we’re trying so hard to preserve!↩︎
We are being slightly informal with the way we draw these dot-error diagrams: cosets of
\mathcal{S} itself inside\mathcal{P}_n don’t make sense, as we’ve said, because\mathcal{S} is generally not normal inside\mathcal{P}_n . Also, when we quotient by\{\pm1,\pm i\} (by drawing just a single sheet, instead of four as in the diagrams in Exercise 7.8.2), we make\mathcal{P} abelian, and this makes the normaliser no longer the actual normaliser.↩︎