14.10 Encoding arbitrary states
The encoding circuit in Figure 14.10 describes a unitary operation (it has no measurements), and its particularly compact form makes it very useful for certain complexity-theoretic calculations, but it has one major drawback: it is not itself protected against errors! If we are trying to design things for the real world, where qubits can undergo decoherence, then we should compensate for this in all our quantum computation, including the circuits we use to prepare states.317 We have already done the hard work for this though, in Section 7.4, when we constructed circuits to project onto Pauli stabiliser spaces. This gives us the encoding circuit in Figure 14.11.
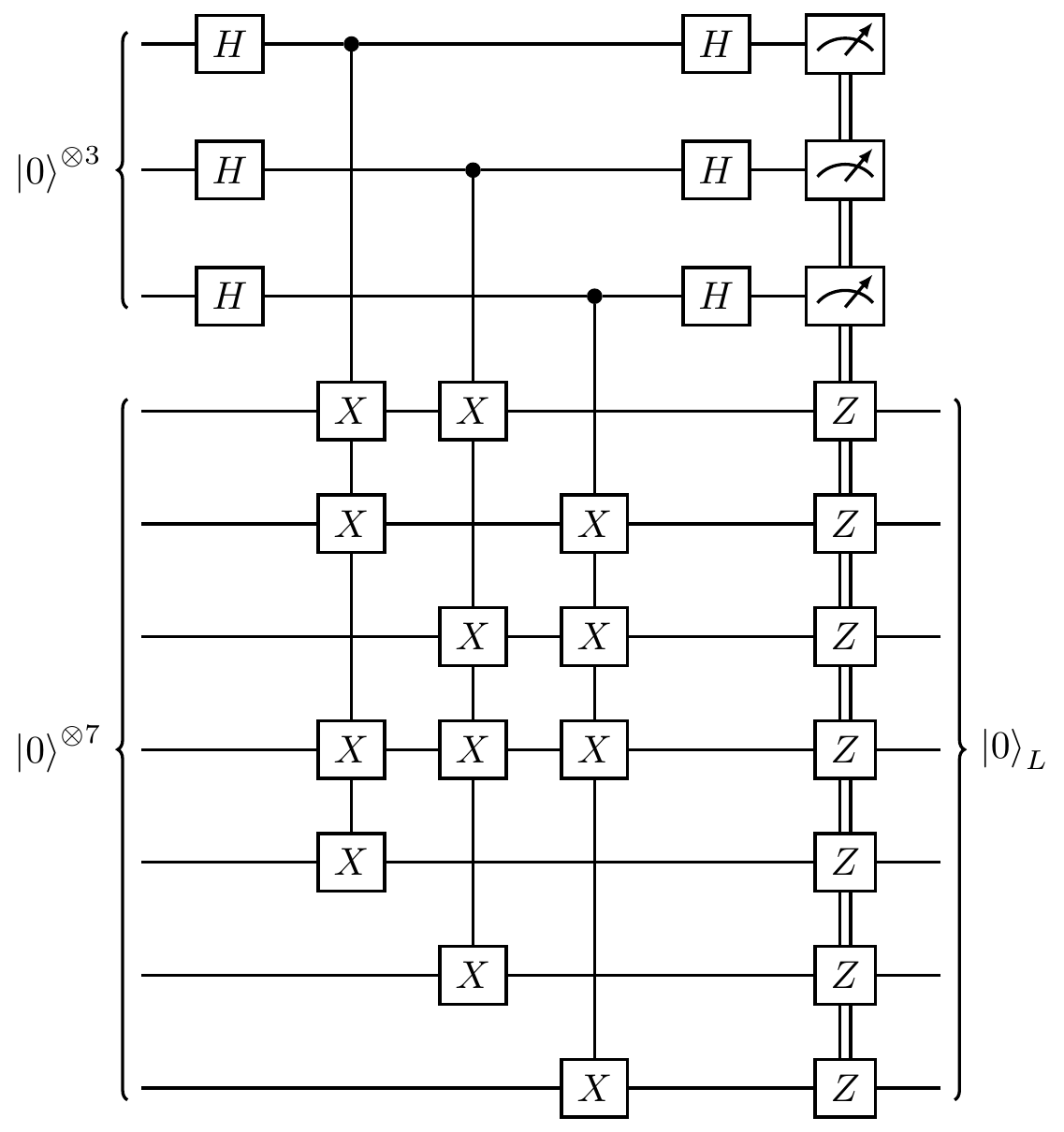
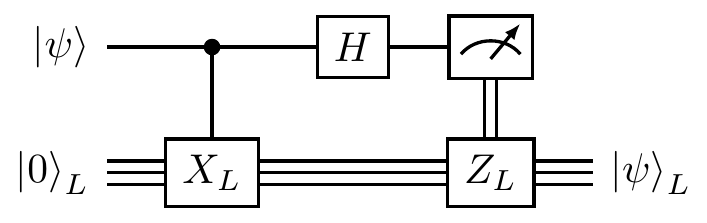
Figure 14.11: Another possible encoding circuit for the Steane code, which uses three ancilla bits for error correction when encoding arbitrary states, but is non-unitary (since it involves measurement). The measurements of the ancilla bits can be used to apply the necessary
The three measurements in the encoding circuit in Figure 14.11 allow us to correct for any single-qubit error in the encoding process, just as we did in Section 7.4, using the lookup table from Section 14.3.
If we measure
So now we have seen two circuits for encoding the logical
Before we look at this question, it’s important to mention something about practical use here.
As is often the case, a chain is only as strong as its weakest link, and the process of encoding a single qubit into seven qubits is a particularly error-prone process.
In practice, it is much more desirable to start with logical
We know that all the
- apply
X_L and then encode - encode and then apply
X_L .
Now let’s generalise this, replacing the
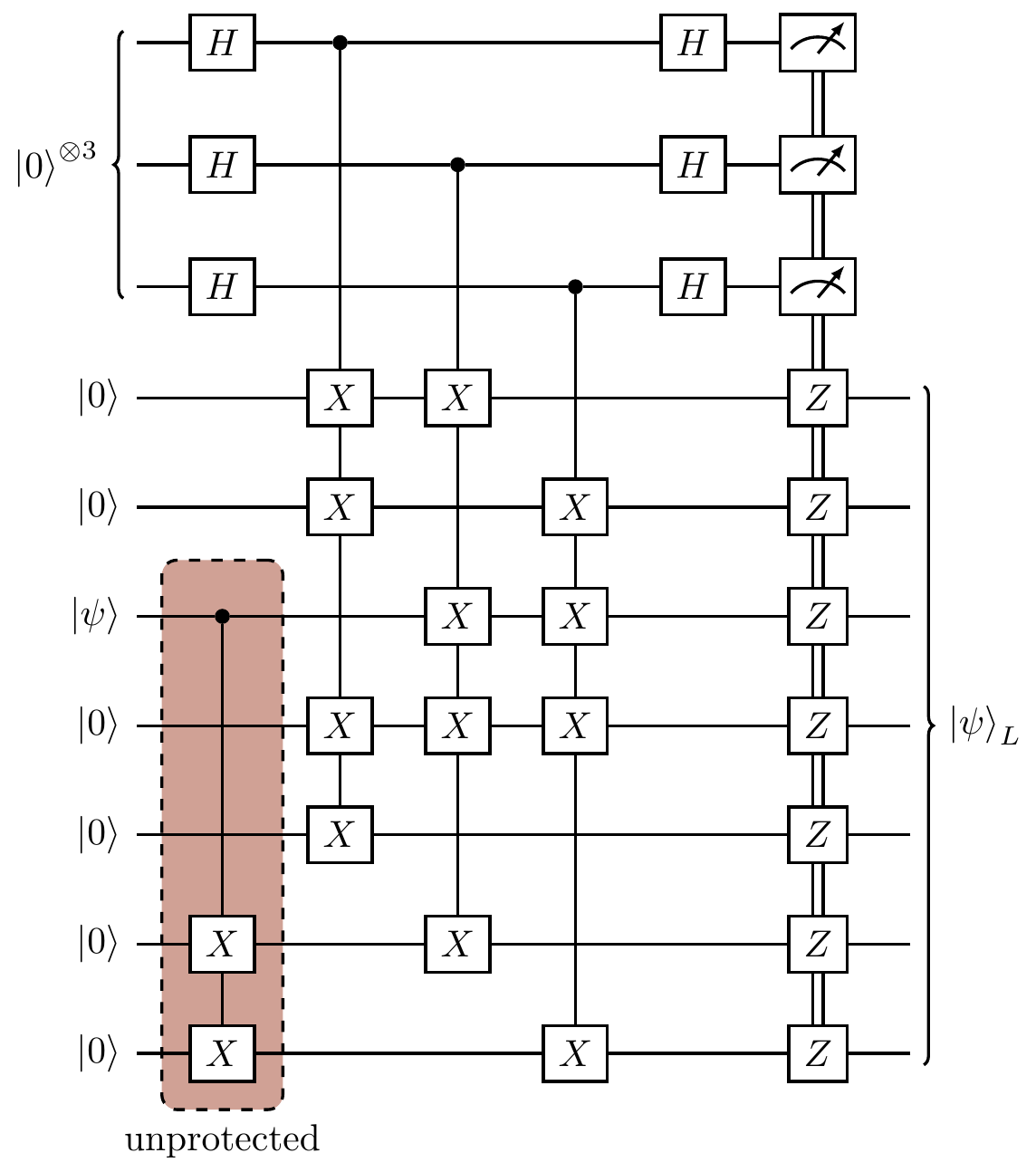
Figure 14.12: Preparing the logical version
To repeat ourselves, the very first step of this circuit that enacts
Now let’s look at the second option from before: encoding and then applying
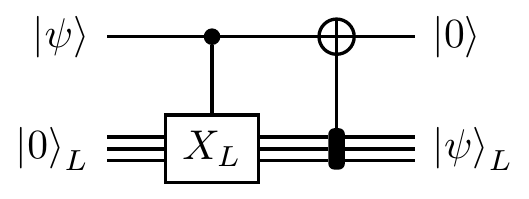
This would transfer the state
The first is reasonably simple: if the control qubit is in state
The second step is maybe not so obvious, but there’s a trick that we can use here!
We know that the top qubit should end in the
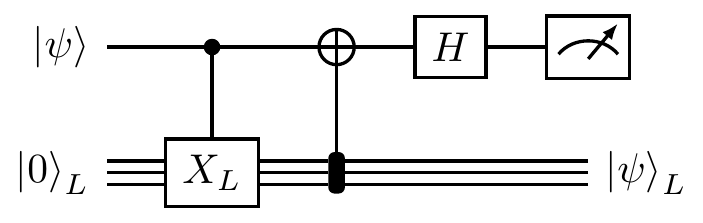
But now we can recall how controlled-
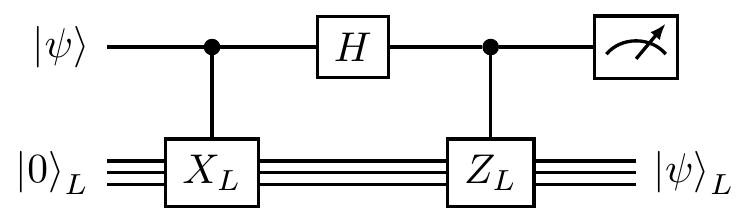
This is a circuit that we could build, since we know all about the many implementations of
If you want people to be able to stay dry if it’s raining, then you might build a tunnel from location A to location B so that they can use this for cover. But this isn’t going to stop people from getting wet on their (necessary) journey from their home to location A!↩︎
What we say here can be applied to other stabiliser codes, but we stick with the Steane code to make it easier to look at specific examples.↩︎
Thanks to the no-cloning theorem (Section 5.9), we know that there is no way of getting around this problem of only having one copy of the state
|\psi\rangle that will work for any possible input — only if|\psi\rangle is something already known. So the preparation part of the circuit doesn’t clone the input state, but instead “smears it out” across three qubits instead of one, just like we mentioned in Section 13.7.↩︎If we want to keep the circuit as simple as possible, then we should choose the smallest weight representative of
X_L , which might not be just a tensor product of allX operators. For example, in the seven-qubit code there is an implementation ofX_L of weight3 .↩︎