14.1 The Hamming code
The challenge in designing efficient error-correcting codes resides in the trade-off between rate and distance (introduced in Section 13.6). Ideally, both quantities should be high: a high rate signifies low overhead in the encoding process (i.e. requiring only a few redundant bits), and a high distance means that many errors can be corrected. So can we optimise both of these quantities simultaneously? Unfortunately, various established bounds tell us that there is always a trade off, so high-rate codes must have low distance, and high-distance codes must have a low rate. Still, there is a lot of ingenuity that goes into designing good error-correction codes, and some are still better than others!
Before looking at quantum codes in more depth, we again start with classical codes.
For example, in Section 13.6 we saw the three-bit repetition code, which has a rate of
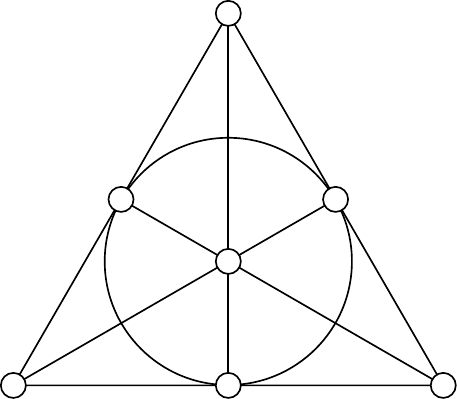
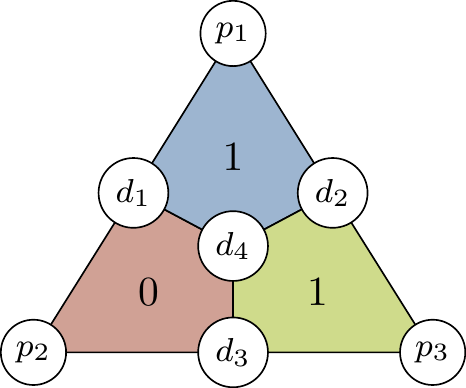
![Left: The Venn diagram for the Hamming [7,4,3] code. Right: The plaquette (or finite projective plane) diagram for the same code. In both, d_i are the data bits and the p_i are the parity bits. The coloured circles (resp. coloured quadrilaterals) are called plaquettes.](qubit_guide_files/figure-html/hamming-code-diagrams-1.png)
Figure 14.1: Left: The Venn diagram for the Hamming
We say that the plaquette diagram in Figure 14.1 could also be called a finite projective plane diagram because of how it resembles the Fano plane, which is the projective space of dimension
In fact, there is more than a mere visual similarity between these two diagrams: we will soon introduce the formal definition of a linear code, and there is a special family of these known as projective codes, which are those such that the columns of the generator matrix (another character who we shall soon meet) are all distinct and non-zero.
Projective codes are particularly interesting because they allow us to apply geometric methods to study the properties of the code. For example, the columns of the parity check matrix of a projective code correspond to points in some projective space. Furthermore, since the geometry in question concerns finite dimensional spaces over finite fields, we end up coming across a lot of familiar (and useful) combinatorics. This is partially due to the fact that finite geometry can be understood as an example of an incidence structure.
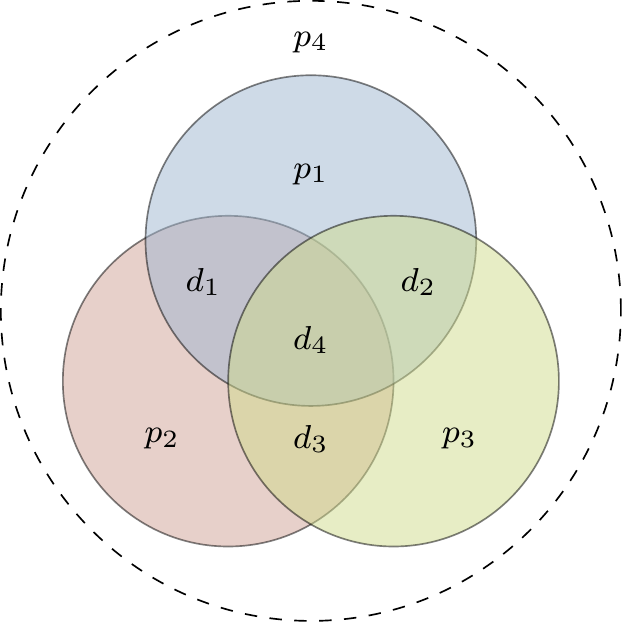
Both diagrams in Figure 14.1 describe the same situation, but although the right-hand one is useful for understanding the geometry hidden in the construction and allowing us to generalise to create new codes, and is thus the one that we will tend to use, the Venn diagram on the left-hand side is maybe more suggestive of what’s going on.
The idea is that we have a four-bit string
We can also express this encoding in matrix notation, defining the data vector
The vector space spanned by the columns of the generator matrix
The encoding process is then given by the matrix
By construction, the sum of the four bits in any single plaquette of the code sum to zero.282
For example, in the bottom-left (red) plaquette,
Let’s consider a concrete example.
Say that Alice encodes her data string
If we make the assumption that at most one error occurs284 then this result tells us exactly where the bit-flip happened: it is not in the bottom-left (red) plaquette, but it is in both the top (blue) and bottom-right (yellow) plaquettes.
Looking at the diagram we see that it must be
We can describe the error location process in terms of matrices as well, using the parity-check matrix285
The parity-check matrix
| Syndrome | ||||||||
|---|---|---|---|---|---|---|---|---|
| Correction | - |
The above construction of the Hamming
Although the Hamming
How does this work?
Well, let’s assume that up to two bit-flip errors could occur.
The decoding process then starts by looking at this new parity bit
Before moving on, it will be useful to introduce another common way of diagrammatically representing parity-check matrices called a Tanner graph.
This is a bipartite graph288 consisting of two types of nodes: the codeword (or data) nodes (one for each bit of the codeword, drawn as circles), and the syndrome nodes (one for each bit of the syndrome, drawn as squares).
The edges in the Tanner graph are such that the parity-check matrix
![The Tanner graph for the Hamming [7,4,3] code. Comparing this to the plaquette diagram in Figure 14.1, we see that we simply replace plaquettes by syndrome nodes (hence our choice of colours). It is not immediately evident that this graph is bipartite, but try drawing it with all the syndrome nodes in one row and all the data nodes in another row below to see that it is.](qubit_guide_files/figure-html/hamming-code-tanner-graph-1.png)
Figure 14.2: The Tanner graph for the Hamming
One particularly useful aspect of Tanner graphs is how simple it is to convert to and from the corresponding parity-check quantum circuits.
There is a syndrome node for each ancilla qubit, and a data node for each data qubit; there are paths between syndrome and data nodes whenever there is a controlled-
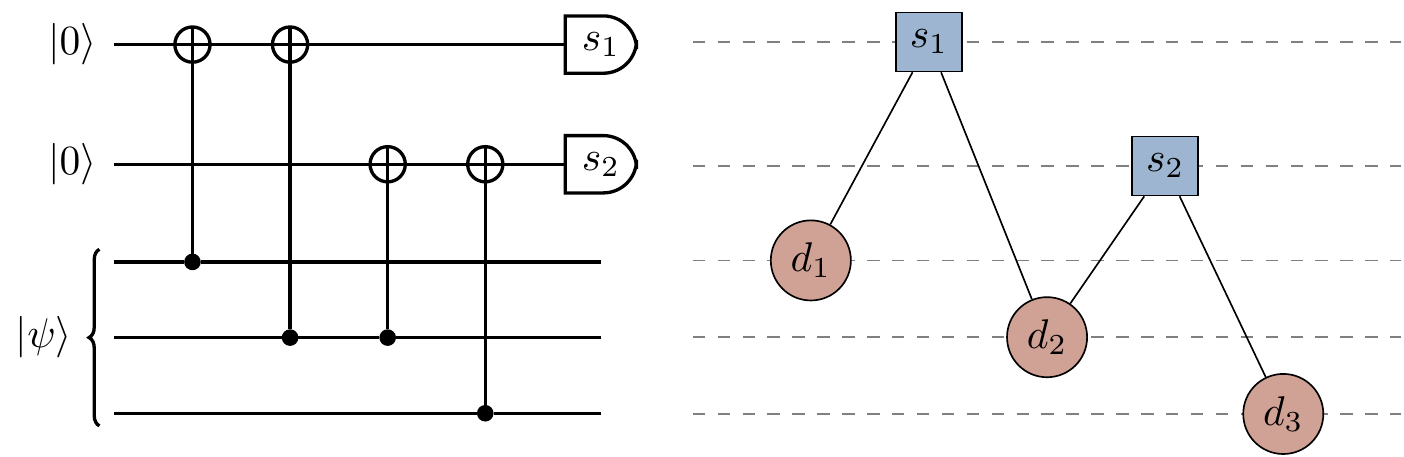
Figure 14.3: Left: The quantum circuit for a parity-check operation. Right: The corresponding Tanner graph.
In the late 1940s, Richard Hamming, working at Bell Labs, was exasperated by the fact that the machines running his punch cards (in these heroic times of computer science, punch cards were the state of the art data storage) were good enough to notice when there was an error (and halting) but not good enough to know how to fix it.↩︎
Sometimes you will see the Hamming
[7,4,3] code referred to simply as the seven-bit Hamming code, the[7,4,3] code, or even just the Hamming code.↩︎Many sources define
G to be the transpose of what we use here, but this is just a question of convention. Because of this, we’ll be dealing with the column (not row) spaces of matrices, also known as the range.↩︎Since we are working with classical bits, all addition is taken
\ \mathrm{mod}\ 2 , so sometimes we will neglect to say this explicitly.↩︎We don’t write the values of the bits, only the sums of the bits in each plaquette. This is because we don’t need to know the value of the bits in order to know where the error is, only the three sums!↩︎
This assumption is crucial here, and we investigate what happens if we drop it in Section 14.7.↩︎
Here is yet another
H , to go with the Hadamard and the Hamiltonian…↩︎Recall that codewords are exactly those vectors of the form
G\mathbf{d} for some data vector\mathbf{d} ↩︎How do we know that the distance is always 3? Well, there are triples of columns in the parity-check matrix that, when added together, give all zeros. This means that there are sets of 3 errors such that, if they all occur together, the syndrome will be zero, and so the distance is no more than 3. Meanwhile, all the columns are distinct, so no pair of columns add together trivially, which means that the distance must be greater than 2.↩︎
A graph (which is a collection of nodes and edges between some of them) is bipartite if the nodes can be split into two sets such that all the edges go from one element of the first set to one element of the second.↩︎