14.5 … and error families
The quotient group297
The cosets of
Again, we can write
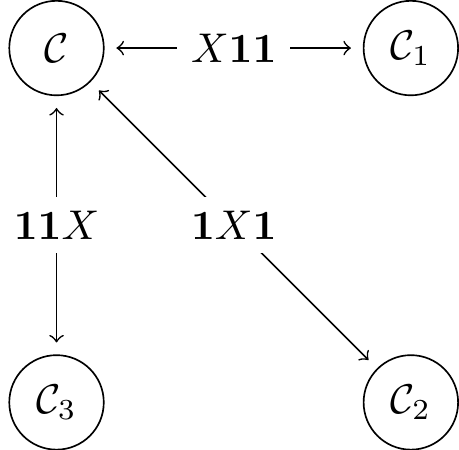
Figure 14.6: The single bit-flip error family
These errors also let us understand how the structure of the codespace is mirrored across each of the cosets.
In other words, we picked
- We can write
\mathcal{C}_1 as the stabiliser space of\mathcal{S} conjugated byX\mathbf{1}\mathbf{1} , i.e.\begin{aligned} (X\mathbf{1}\mathbf{1})\langle ZZ\mathbf{1}, \mathbf{1}ZZ \rangle(X\mathbf{1}\mathbf{1})^{-1} &= \langle (X\mathbf{1}\mathbf{1})(ZZ\mathbf{1})(X\mathbf{1}\mathbf{1})^{-1}, (X\mathbf{1}\mathbf{1})(\mathbf{1}ZZ)(X\mathbf{1}\mathbf{1})^{-1} \rangle \\&= \langle -ZZ\mathbf{1}, \mathbf{1}ZZ \rangle \end{aligned} and, indeed,|100\rangle and|011\rangle are both stabilised by this group. - The logical states of
\mathcal{C}_1 are, by definition as our chosen basis, the elements|100\rangle and|011\rangle , but note that these are exactly the images of the logical states of\mathcal{C} under the errorX\mathbf{1}\mathbf{1} , i.e.\begin{aligned} |0\rangle_{L,1} &\coloneqq |100\rangle = X\mathbf{1}\mathbf{1}|000\rangle \\|1\rangle_{L,1} &\coloneqq |011\rangle = X\mathbf{1}\mathbf{1}|111\rangle \end{aligned} - The logical operators on
\mathcal{C}_1 are the logical operators on\mathcal{C} conjugated byX\mathbf{1}\mathbf{1} , i.e\begin{aligned} X_{L,1} &\coloneqq (X\mathbf{1}\mathbf{1})(XXX)(X\mathbf{1}\mathbf{1})^{-1} \\&= XXX \\Z_{L,1} &\coloneqq (X\mathbf{1}\mathbf{1})(ZZZ)(X\mathbf{1}\mathbf{1})^{-1} \\&= -ZZZ \end{aligned} and, indeed,X_{L,1} andZ_{L,1} behave as expected on the new logical states, i.e.\begin{aligned} X_{L,1}\colon |0\rangle_{L,1} &\longmapsto |1\rangle_{L,1} \\|1\rangle_{L,1} &\longmapsto |0\rangle_{L,1} \\Z_{L,1}\colon |0\rangle_{L,1} &\longmapsto |0\rangle_{L,1} \\|1\rangle_{L,1} &\longmapsto -|1\rangle_{L,1} \end{aligned} as you can check by hand.
All in all, the chain of normal subgroups
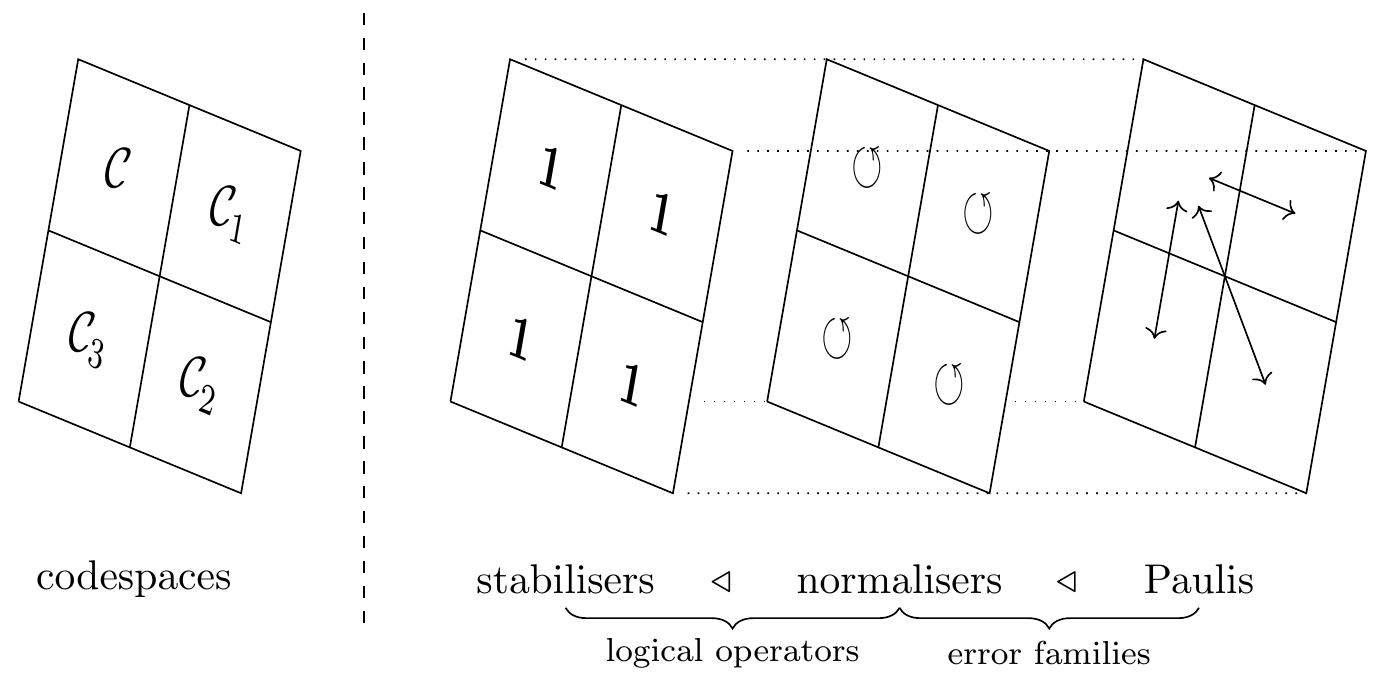
Figure 14.7: A visualisation of how the stabilisers, normalisers, and arbitrary Pauli operators act on the codespace decomposition: stabilisers act as the identity, normalisers move each subspace around within itself, and Pauli operators swap subspaces around between one another.
But this stabiliser formalism introduces some new ambiguity.
In Section 14.3, we saw how measuring the three ancilla qubits in the Hamming
As you might expect, the story is not yet over. Depending on the specifics of the scenario, sometimes knowing the error family is enough to be able to correct not just one physical error, but many. In order to give a more precise explanation, we need to take a step back and look at the scenarios that we’re actually trying to model — we do this in Section 14.7.
Recall that the elements of the quotient group
G/H are exactly the cosets ofH\triangleleft G .↩︎We sometimes denote the coset
P\cdot N(\mathcal{S}) simply by[P] , just to save space.↩︎Recall that conjugation expresses a change of basis: given an invertible
(n\times n) matrixB , we can turn a basis\{v_1,\ldots,v_n\} into a new basis\{Bv_1,\ldots,Bv_n\} , and to write any operatorA in this new basis we simply calculateBAB^{-1} (“undo the change of basis, applyA , then redo the change of basis”).↩︎